
1. Introduction
Tech for Non-Tech: Understanding the Data Lakehouse Revolution
In today’s data-driven world, the ability to harness and manage vast amounts of information has become a critical differentiator for businesses. Modern enterprises are generating and collecting data at unprecedented scales, leading to increasingly complex data management challenges. This complexity is further compounded by the diverse nature of the data itself, which ranges from structured datasets residing in relational databases to unstructured data such as text, images, and videos. The growing demand for real-time analytics, machine learning, and business intelligence has made traditional data management solutions increasingly inadequate.
For years, organizations have relied on two primary architectures to manage and analyze their data: data warehouses and data lakes. Data warehouses have been instrumental in storing and processing structured data, offering optimized performance for complex queries and reporting. They provide a high degree of reliability and are well-suited for transactional data that requires consistency and integrity. However, they often struggle with scalability and are less effective when dealing with unstructured or semi-structured data.
On the other hand, data lakes emerged as a solution to store vast amounts of raw data in its native format, allowing organizations to handle both structured and unstructured data types. Data lakes offer greater flexibility and are highly scalable, making them ideal for big data analytics and machine learning. However, they come with their own set of challenges, such as data governance, security, and the lack of performance optimization for real-time analytics.
As the data landscape continues to evolve, the limitations of these traditional approaches have become more apparent. Enterprises are now seeking more integrated solutions that can provide the reliability and performance of a data warehouse, along with the scalability and flexibility of a data lake. This growing demand has led to the emergence of a new architectural paradigm—the Data Lakehouse.
Purpose of the Article:
The purpose of this article is to introduce the concept of a Data Lakehouse, a modern data architecture that combines the strengths of both data warehouses and data lakes while addressing their respective limitations. The Data Lakehouse represents a significant evolution in the way organizations manage, process, and analyze their data, making it a critical technology for businesses aiming to stay competitive in a data-driven world.
We will explore what a Data Lakehouse is, its importance in today’s data ecosystem, and why it is rapidly being adopted by organizations across various industries. The article will also highlight the key differences between data warehouses, data lakes, and data lakehouses, providing a clear understanding of how each architecture serves different data needs.
Moreover, this article will provide practical guidance on whether and how to adopt a Data Lakehouse architecture. We will discuss the key features and benefits of a Data Lakehouse, how it is architecturally advanced, and who should consider adopting this technology. Finally, we will outline the major players in the Data Lakehouse space and offer insights into how organizations can migrate from existing data warehouses or data lakes to a Data Lakehouse.
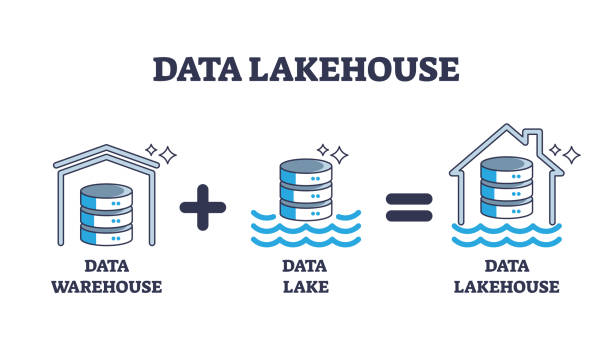
2. What is a Data Lakehouse?
Definition:
A Data Lakehouse is a modern data architecture that merges the most advantageous features of data warehouses and data lakes into a single, unified platform. This architecture is designed to handle the full spectrum of data types, from highly structured transactional data to unstructured content such as logs, images, and videos. The core idea behind a Data Lakehouse is to eliminate the trade-offs traditionally associated with using separate systems for data storage and analytics by providing a seamless environment where data can be stored, managed, and analyzed efficiently and effectively.
At its essence, a Data Lakehouse enables organizations to store large amounts of raw data, just like a data lake, while also offering the transactional reliability, performance, and data management capabilities of a data warehouse. This combination makes it possible to perform complex queries, data analytics, and machine learning tasks all within the same architecture, without needing to move data across different systems.
Core Concept:
One of the primary innovations of the Data Lakehouse architecture is its ability to integrate both structured and unstructured data into a single platform. Traditional data warehouses are optimized for structured data, which is organized in a specific format (such as rows and columns). However, modern businesses generate vast amounts of unstructured data—like social media posts, customer reviews, images, and sensor data—that do not fit neatly into the rigid schema of a traditional database.
Data lakes, on the other hand, were developed to address the need for storing this unstructured data. They provide a scalable and cost-effective solution by allowing data to be ingested in its raw format, without the need for upfront schema design. However, data lakes often suffer from issues related to data governance, quality, and performance, especially when it comes to real-time analytics.
A Data Lakehouse bridges this gap by allowing both structured and unstructured data to coexist within the same environment. It achieves this through a combination of storage and processing technologies that support a wide range of data types and formats. For example, a Data Lakehouse can store structured transactional data in a format optimized for fast query performance, while also storing unstructured data in a format that can be easily accessed and processed by machine learning algorithms or other analytical tools.
Another key aspect of the Data Lakehouse is its support for both transactional and analytical workloads. In traditional architectures, these workloads are typically handled by separate systems: data warehouses for analytical processing (OLAP) and transactional databases for operational processing (OLTP). The Data Lakehouse integrates these capabilities, allowing for ACID (Atomicity, Consistency, Isolation, Durability) transactions, which are crucial for maintaining data integrity in real-time applications, alongside the ability to perform complex analytical queries on large datasets.
This dual capability means that a Data Lakehouse can serve as the backbone for a wide variety of use cases, from running business intelligence reports and dashboards to supporting advanced analytics, machine learning, and artificial intelligence. It provides a more flexible and efficient way to manage data, eliminating the need to move data between different systems and reducing latency in data processing and decision-making.
Data Lakehouse is a unified data platform that combines the scalability and flexibility of data lakes with the performance and reliability of data warehouses. By integrating structured and unstructured data and supporting both transactional and analytical workloads, the Data Lakehouse offers a powerful solution for modern data management challenges. This architecture enables organizations to derive more value from their data, improve operational efficiency, and innovate faster by providing a single platform for all their data needs.
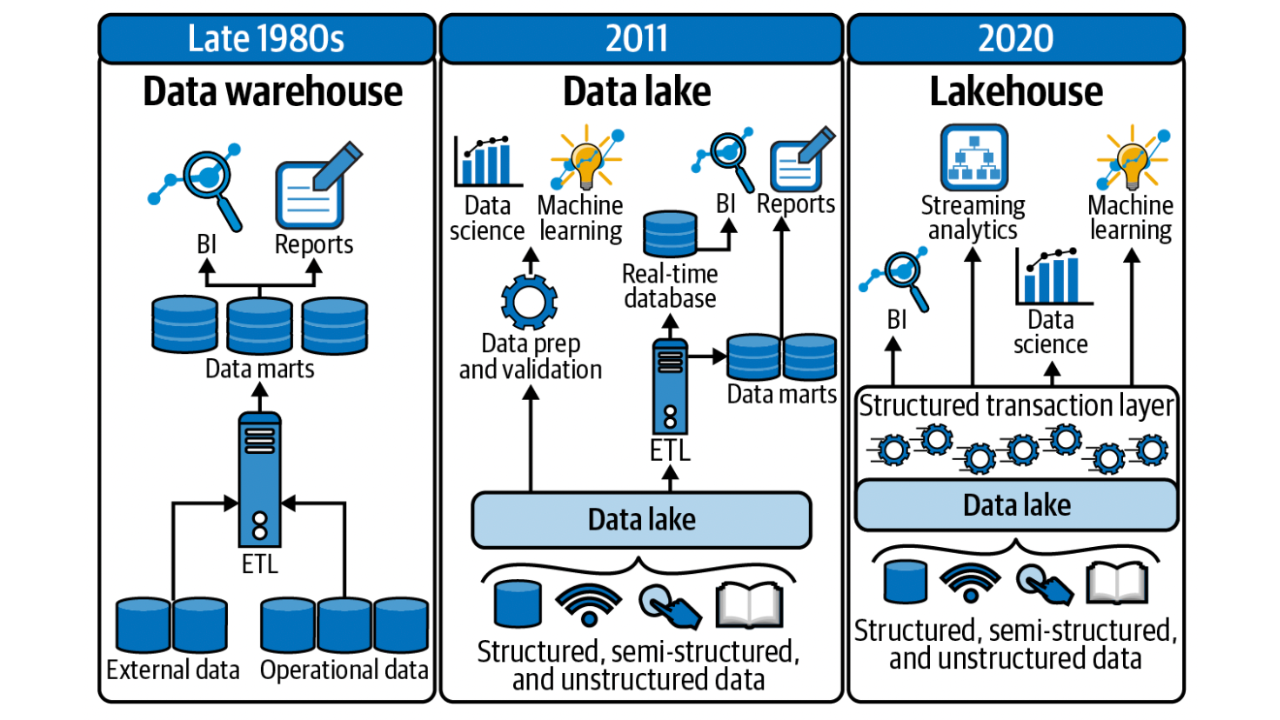
3. Why is a Data Lakehouse Important?
The importance of a Data Lakehouse lies in its ability to address the fundamental challenges that organizations face in managing and deriving value from their data. By unifying the capabilities of data lakes and data warehouses into a single architecture, a Data Lakehouse offers several key benefits that make it a vital technology for modern enterprises.
Unified Data Management:
One of the primary challenges of traditional data architectures is the separation of data lakes and data warehouses. Data lakes are designed for storing large volumes of raw data in its native format, making them ideal for big data analytics and machine learning. However, data lakes often lack the performance optimizations and data governance features necessary for transactional data processing and real-time analytics. On the other hand, data warehouses are optimized for structured data and complex queries, providing robust data management and high-performance analytics. However, they are typically more expensive to scale and less flexible when it comes to handling unstructured or semi-structured data.
This separation creates several problems:
- Data Silos: Data is often fragmented across different systems, leading to silos where data stored in a data lake cannot be easily accessed or queried by the tools and processes that rely on the data warehouse, and vice versa.
- Redundancy: The need to duplicate data across multiple systems increases storage costs and complicates data management, as data must be kept in sync across different environments.
- Complexity: Managing and integrating separate systems for data storage, processing, and analytics introduces significant complexity, requiring specialized skills and resources to maintain and operate effectively.
A Data Lakehouse addresses these issues by providing a unified platform where both structured and unstructured data can coexist and be managed together. This eliminates data silos, reduces redundancy, and simplifies the overall data architecture, making it easier for organizations to manage their data and derive insights from it.
Cost Efficiency:
Maintaining separate data lakes and data warehouses is not only complex but also costly. Data warehouses, with their optimized storage and high-performance query capabilities, can be expensive to scale, especially when dealing with large volumes of data. Data lakes, while more cost-effective in terms of storage, often require additional investments in data processing and governance tools to ensure data quality and accessibility.
By combining data storage and analytics in a single system, a Data Lakehouse can significantly reduce costs. Organizations no longer need to invest in and maintain multiple data platforms, which reduces both capital expenditure (CapEx) and operational expenditure (OpEx). Additionally, the ability to store data in its raw format and apply schema-on-read processing means that organizations can avoid the upfront costs associated with data transformation and schema design, further reducing expenses.
Moreover, because a Data Lakehouse allows for real-time data processing and analytics, it can help organizations avoid the costs associated with delayed decision-making and missed opportunities. The ability to derive insights from data as it is generated can lead to more timely and informed business decisions, ultimately driving greater value and competitive advantage.
Scalability and Flexibility:
In today’s fast-paced business environment, the ability to scale and adapt to changing data needs is crucial. Traditional data warehouses, while powerful, can be difficult and costly to scale, particularly when dealing with unstructured data or large volumes of semi-structured data. Data lakes, on the other hand, offer greater scalability but often at the expense of performance and data management capabilities.
A Data Lakehouse provides the best of both worlds, offering the scalability of a data lake with the performance and reliability of a data warehouse. This architecture can easily scale with an organization’s data needs, accommodating growing volumes of data and diverse data types. Whether an organization is dealing with structured transactional data, unstructured media files, or semi-structured log data, a Data Lakehouse can store, process, and analyze it all within a single platform.
Furthermore, the flexibility of a Data Lakehouse allows organizations to adapt to new use cases and data sources without needing to invest in additional infrastructure or rearchitect their data environment. This makes it easier to integrate new data sources, support emerging technologies like machine learning and AI, and respond to changing business requirements.
Streamlined Data Processing:
Data processing in traditional architectures often involves complex ETL (Extract, Transform, Load) processes, where data must be extracted from a source system, transformed to fit the schema of the target system, and then loaded into the data warehouse for analysis. These processes can be time-consuming, resource-intensive, and prone to errors, especially as the volume and variety of data increase.
A Data Lakehouse simplifies and streamlines data processing by reducing the need for complex ETL workflows. In a Data Lakehouse, data can be ingested in its raw format and processed in real-time, allowing for immediate analysis and decision-making. This approach not only speeds up the time to insight but also reduces the operational overhead associated with managing ETL processes.
The ability to perform real-time data processing and analysis is particularly valuable in today’s fast-moving business environment, where organizations need to respond quickly to changing market conditions and customer demands. By enabling faster and more efficient data processing, a Data Lakehouse empowers organizations to make more informed decisions, improve operational efficiency, and stay ahead of the competition.
In summary, a Data Lakehouse is important because it addresses the key challenges of traditional data architectures by providing unified data management, cost efficiency, scalability, flexibility, and streamlined data processing. These benefits make the Data Lakehouse a powerful and versatile solution for modern enterprises, enabling them to manage and analyze their data more effectively and derive greater value from it.
4. How Does a Data Lakehouse Differ from a Data Warehouse and Data Lake?
To fully appreciate the innovation behind the Data Lakehouse, it’s essential to understand how it differs from the traditional data warehouse and data lake architectures. Each of these architectures has its own strengths and weaknesses, which the Data Lakehouse seeks to unify and enhance.
Data Warehouse:
Definition: A data warehouse is a centralized repository designed for storing structured data that has been cleaned, transformed, and organized into predefined schemas, typically in a relational database format. It is optimized for Online Analytical Processing (OLAP), making it ideal for running complex queries, generating reports, and performing business intelligence (BI) tasks.
Traditional Use Cases: Data warehouses are widely used in industries where structured data and transactional consistency are paramount. Common use cases include:
- Business Reporting and Dashboards: Organizations use data warehouses to generate detailed reports and dashboards that provide insights into sales, financials, and operational metrics.
- Data Analysis: Analysts rely on data warehouses to perform historical data analysis, trend analysis, and other forms of data exploration.
- Regulatory Compliance: Due to their ability to handle structured data and maintain data integrity, data warehouses are often used for regulatory reporting in industries like finance, healthcare, and retail.
Strengths:
- Structured Data Handling: Data warehouses are highly effective at managing and querying structured data, such as transactional records, financial data, and other tabular data.
- Query Performance: They are designed for high-performance querying, enabling fast and efficient data retrieval for complex analytical queries.
- Data Integrity: Data warehouses enforce strict data governance and schema consistency, ensuring that data is reliable and adheres to predefined rules.
Limitations:
- Cost: Scaling a data warehouse to handle large volumes of data, especially unstructured data, can be prohibitively expensive due to the need for specialized hardware and software.
- Complexity in Handling Unstructured Data: Data warehouses struggle with unstructured or semi-structured data, such as images, videos, and logs, requiring extensive data transformation and preprocessing to fit into a structured schema.
- Rigidity: The predefined schemas of data warehouses can be inflexible, making it challenging to accommodate new data types or rapidly changing business requirements.
Data Lake:
Definition: A data lake is a large-scale storage repository that can hold vast amounts of raw data in its native format, including structured, semi-structured, and unstructured data. Unlike data warehouses, data lakes do not require data to be transformed or organized before storage, allowing for greater flexibility and scalability.
Use Cases: Data lakes are typically used in scenarios where there is a need to store and process large volumes of diverse data types. Common use cases include:
- Big Data Analytics: Data lakes are ideal for big data processing frameworks like Apache Hadoop and Spark, which can handle large datasets and perform distributed processing tasks.
- Machine Learning and AI: Data scientists use data lakes to store and access raw data needed for training machine learning models and conducting advanced analytics.
- Data Archiving: Organizations use data lakes to archive large amounts of data that may not be immediately needed but could be valuable for future analysis.
Strengths:
- Handling Unstructured Data: Data lakes excel at storing unstructured and semi-structured data, such as text, images, videos, and sensor data, without requiring any upfront schema design.
- Scalability: Data lakes are highly scalable, capable of storing petabytes of data at a relatively low cost, making them suitable for big data environments.
- Flexibility: Because data is stored in its raw format, data lakes offer flexibility in how data is used and processed. Different tools and frameworks can access the same data for various purposes.
Limitations:
- Lack of Transactional Support: Data lakes do not natively support ACID transactions, which are crucial for ensuring data consistency and reliability in transactional workloads.
- Query Performance Issues: While data lakes are great for storing raw data, they are not optimized for querying and analytics, often resulting in slower query performance compared to data warehouses.
- Data Governance Challenges: Managing data quality, security, and governance in a data lake can be challenging due to the lack of enforced schemas and the diverse nature of the stored data, leading to potential data swamps where the data becomes difficult to manage and use.
Data Lakehouse:
How It Merges the Benefits of Both Data Lakes and Warehouses: A Data Lakehouse represents a new paradigm that merges the strengths of data lakes and data warehouses, creating a unified architecture that overcomes the limitations of both. It provides a single platform where all types of data—structured, semi-structured, and unstructured—can be stored, processed, and analyzed.
Hybrid Storage Formats: One of the key innovations of the Data Lakehouse is its ability to support hybrid storage formats. This means that data can be stored in its raw format (as in a data lake) while also being indexed and optimized for high-performance querying (as in a data warehouse). For example, a Data Lakehouse can use formats like Parquet or ORC for structured data, enabling efficient data compression and query optimization, while also supporting open formats like JSON or Avro for semi-structured data.
Support for ACID Transactions: Unlike traditional data lakes, a Data Lakehouse supports ACID transactions, ensuring that data operations are reliable, consistent, and safe from corruption. This is particularly important for scenarios where data integrity is critical, such as financial transactions or real-time data processing. By supporting ACID transactions, a Data Lakehouse ensures that data can be updated and queried simultaneously without compromising accuracy or consistency.
Unified Governance: A Data Lakehouse also provides unified data governance, combining the robust data management features of a data warehouse with the scalability of a data lake. This means that data security, access controls, and compliance policies can be applied consistently across all data, regardless of its type or source. This unified governance model simplifies data management and ensures that all data within the organization is subject to the same standards and controls.
The Data Lakehouse architecture combines the best aspects of both data lakes and data warehouses, offering a versatile and powerful solution for modern data management challenges. By merging the flexibility and scalability of data lakes with the performance and reliability of data warehouses, a Data Lakehouse provides a unified platform that can handle all types of data and support a wide range of use cases. This makes it an ideal choice for organizations looking to streamline their data architecture, reduce costs, and accelerate their data-driven initiatives.

5. Key Features of a Data Lakehouse
A Data Lakehouse combines the strengths of data warehouses and data lakes, bringing together a set of advanced features that make it a compelling solution for modern data management needs. These features are designed to ensure data reliability, flexibility, security, and scalability, while enabling organizations to derive immediate and actionable insights from their data.
ACID Transactions:
Ensure Data Reliability and Consistency: One of the foundational features of a Data Lakehouse is its support for ACID (Atomicity, Consistency, Isolation, Durability) transactions. In traditional data lakes, data operations often lack transactional guarantees, which can lead to issues like data corruption, inconsistency, and unreliable query results. A Data Lakehouse overcomes these challenges by incorporating ACID compliance, ensuring that all data operations are executed reliably and that the data remains consistent, even in the face of concurrent transactions or system failures.
This feature is particularly crucial for scenarios that require high levels of data accuracy and integrity, such as financial transactions, inventory management, or real-time analytics. With ACID transactions, organizations can confidently run complex workloads on their Data Lakehouse, knowing that the data will be accurate and consistent across all operations.
Unified Governance and Security:
Single Platform for Managing Data Access and Compliance: Data governance and security are critical concerns for organizations, especially as data privacy regulations become more stringent and the volume of sensitive data grows. A Data Lakehouse provides a unified platform for managing data governance and security across all data types—structured, semi-structured, and unstructured. This centralized approach simplifies the enforcement of data access controls, auditing, and compliance policies, ensuring that data is protected and that organizations can meet regulatory requirements.
Unified governance also means that data lineage, metadata management, and data cataloging are integrated into the platform, making it easier for organizations to track data usage, ensure data quality, and provide transparency into how data is being utilized across the enterprise. This level of control is essential for maintaining trust in data and for supporting initiatives like data democratization, where more users are granted access to data for self-service analytics.
Support for Structured and Unstructured Data:
Flexibility in Data Ingestion and Management: One of the key differentiators of a Data Lakehouse is its ability to handle a wide variety of data types within a single platform. Unlike traditional data warehouses, which are optimized for structured data, or data lakes, which are designed primarily for unstructured data, a Data Lakehouse can ingest, store, and manage both types of data effectively.
This flexibility allows organizations to bring together data from disparate sources—such as transactional databases, log files, social media feeds, and multimedia content—into a unified environment. By supporting both structured and unstructured data, a Data Lakehouse enables more comprehensive analytics and machine learning capabilities, as users can combine different types of data to gain deeper insights and create more sophisticated models.
Real-Time Data Processing:
Enable Immediate Insights with Streaming and Batch Processing: In today’s fast-paced business environment, the ability to process and analyze data in real-time is a critical competitive advantage. A Data Lakehouse is designed to support both streaming and batch data processing, enabling organizations to derive immediate insights from their data as it is generated.
For example, with real-time data processing, a retail company can analyze customer behavior as transactions occur, allowing it to make instant recommendations or detect fraud. Similarly, a manufacturing company can monitor sensor data from its equipment in real-time to predict and prevent failures before they happen.
The combination of real-time processing with the ability to handle large-scale batch processing tasks makes a Data Lakehouse a versatile platform for a wide range of use cases, from operational intelligence to advanced analytics and machine learning.
Scalability:
Handle Growing Data Volumes and Diverse Workloads Efficiently: Scalability is another cornerstone of the Data Lakehouse architecture. As organizations collect and generate more data, they need a platform that can scale to accommodate increasing data volumes and more complex workloads without compromising performance or incurring prohibitive costs.
A Data Lakehouse is built on scalable cloud-native technologies that allow it to grow seamlessly with an organization’s data needs. Whether it’s adding more storage capacity to handle petabytes of data or scaling compute resources to support intensive machine learning workloads, a Data Lakehouse can efficiently manage growth while maintaining high levels of performance.
This scalability also extends to the variety of workloads that a Data Lakehouse can support. From simple data queries and reporting to large-scale data transformation and machine learning, a Data Lakehouse provides the flexibility and power needed to handle diverse use cases within a single, unified platform.
In summary, the key features of a Data Lakehouse—ACID transactions, unified governance and security, support for structured and unstructured data, real-time data processing, and scalability—make it an advanced and versatile architecture for modern data management. These features enable organizations to manage their data more effectively, derive insights more quickly, and scale their operations to meet the demands of a data-driven world. By adopting a Data Lakehouse, organizations can position themselves to better leverage their data assets, improve decision-making, and drive innovation.

6. Architectural Advancements and Benefits
The Data Lakehouse architecture introduces several significant advancements that enhance data management, improve performance, and support future growth. By integrating the best aspects of data lakes and data warehouses, a Data Lakehouse offers a more streamlined, efficient, and adaptable solution for managing and analyzing data.
Simplified Architecture:
Integration of Storage and Analytics Reduces Complexity: One of the most notable architectural advancements of the Data Lakehouse is its ability to unify storage and analytics into a single platform. Traditional data architectures often involve a combination of data lakes for raw data storage and data warehouses for analytics, which can create complex and fragmented systems that are challenging to manage.
A Data Lakehouse simplifies this architecture by consolidating these functions into one system. This integration eliminates the need for data duplication between separate platforms, reduces the complexity of data management, and streamlines operations. With a unified data platform, organizations can more easily maintain data consistency, manage data workflows, and ensure that all users have access to the same dataset. This streamlined approach not only simplifies data architecture but also reduces operational overhead and associated costs.
Performance Optimization:
Discuss Optimizations Like Indexing, Caching, and Query Acceleration: To address the performance challenges associated with traditional data lakes and warehouses, a Data Lakehouse incorporates various optimization techniques that enhance data retrieval and processing speeds. Key performance optimizations include:
- Indexing: Data Lakehouses utilize advanced indexing techniques to improve query performance. Indexes help to quickly locate and retrieve relevant data without having to scan the entire dataset. This is particularly useful for complex queries and large-scale analytics, where quick access to specific data points is crucial.
- Caching: Caching mechanisms are employed to store frequently accessed data in memory, reducing the time required to retrieve data from disk storage. By keeping commonly queried data readily available, caching improves response times and overall system performance.
- Query Acceleration: Data Lakehouses often implement query acceleration technologies, such as columnar storage formats and query optimization engines, to speed up data processing. These technologies optimize how data is stored and accessed, enabling faster execution of analytical queries and reports.
These performance optimizations ensure that a Data Lakehouse can handle a high volume of queries and analytics efficiently, providing users with timely insights and maintaining high levels of system responsiveness.
Data Democratization:
How Lakehouses Enable Broader Access to Data for Non-Technical Users Through Simplified Query Tools: A key advantage of the Data Lakehouse architecture is its ability to support data democratization, which involves making data more accessible and usable by a broader range of users within an organization. By providing simplified query tools and interfaces, Data Lakehouses enable non-technical users to interact with and analyze data without needing deep technical expertise.
Data Lakehouses often come equipped with user-friendly query tools, such as SQL-based interfaces, drag-and-drop analytics, and visual dashboards, that allow users to perform data exploration and analysis with ease. These tools enable business users, analysts, and other non-technical staff to generate insights, create reports, and make data-driven decisions independently.
Furthermore, the unified data platform of a Data Lakehouse ensures that all users have access to a consistent and comprehensive dataset, reducing data silos and improving collaboration across departments. By democratizing data access, organizations can empower more employees to leverage data in their roles, leading to better decision-making and more innovative problem-solving.
Future-Proofing Data Strategy:
How Lakehouses Prepare Organizations for Future Data Growth and Evolving Use Cases: As organizations continue to generate and collect increasing volumes of data, it is essential to have a data architecture that can scale and adapt to future needs. The Data Lakehouse is designed with future-proofing in mind, offering several features that prepare organizations for ongoing data growth and evolving use cases:
- Scalability: Data Lakehouses are built on cloud-native technologies that provide scalable storage and compute resources. This allows organizations to easily accommodate growing data volumes and expanding workloads without requiring significant infrastructure changes or investments.
- Flexibility: The architecture supports a wide range of data types and processing needs, from traditional BI and reporting to advanced analytics and machine learning. This flexibility enables organizations to adapt to new data use cases and emerging technologies as they arise.
- Modular Design: Many Data Lakehouses feature a modular design that allows for the integration of new tools and technologies. This modularity ensures that organizations can incorporate the latest innovations and capabilities into their data environment without needing to overhaul their entire system.
By incorporating these future-proofing features, a Data Lakehouse helps organizations stay agile and responsive to changing business requirements and technological advancements. This readiness ensures that the data architecture remains relevant and effective as the organization’s data needs evolve over time.
The architectural advancements of the Data Lakehouse—simplified architecture, performance optimization, data democratization, and future-proofing—offer significant benefits for modern data management. By integrating storage and analytics into a single platform, optimizing performance, broadening data access, and preparing for future growth, a Data Lakehouse provides a robust and adaptable solution for managing and leveraging data in today’s dynamic business environment.

7. Who Should Adopt a Data Lakehouse?
The Data Lakehouse is a versatile and advanced data architecture that offers significant advantages for various types of organizations. Its ability to unify storage and analytics, handle diverse data types, and scale efficiently makes it an ideal choice for several key scenarios. Here’s a closer look at who can benefit most from adopting a Data Lakehouse:
Enterprises with Diverse Data Needs:
Large Organizations Dealing with Both Structured and Unstructured Data: Large enterprises often face the challenge of managing a vast array of data types, from traditional structured data (like transactional records and financial data) to unstructured data (such as social media posts, emails, and multimedia content). Traditional data warehouses are optimized for structured data, while data lakes are designed for unstructured data. However, the need to manage and analyze both types of data in an integrated manner can create complexity and inefficiencies.
A Data Lakehouse addresses this challenge by providing a unified platform that can store, process, and analyze both structured and unstructured data. This integration reduces the need for data silos, minimizes data duplication, and simplifies data management. Large enterprises benefit from a Data Lakehouse by achieving a more coherent data environment where all data types can be accessed and analyzed seamlessly, leading to more comprehensive insights and better decision-making.
Industries with High Data Complexity:
Examples: Financial Services, Healthcare, Retail: Certain industries are characterized by high data complexity due to regulatory requirements, diverse data sources, and the need for real-time insights. These industries can particularly benefit from the capabilities of a Data Lakehouse:
- Financial Services: The financial industry generates and processes vast amounts of structured data (e.g., transaction records, account information) as well as unstructured data (e.g., customer feedback, market news). A Data Lakehouse can streamline compliance reporting, fraud detection, and risk management by providing a unified view of all data types, with the ability to perform real-time analytics and support complex queries.
- Healthcare: In healthcare, data is collected from various sources including electronic health records (EHRs), medical imaging, patient surveys, and research studies. The Data Lakehouse’s ability to integrate and analyze diverse data types helps healthcare organizations improve patient care, streamline operations, and conduct more effective research while ensuring compliance with stringent regulations.
- Retail: Retailers deal with structured data from sales transactions and inventory management, as well as unstructured data from customer reviews, social media, and online interactions. A Data Lakehouse enables retailers to gain a holistic view of customer behavior, optimize supply chains, and personalize marketing efforts by combining and analyzing all types of data within a single platform.
Growing Companies:
Startups and Mid-Sized Companies Preparing for Scaling Their Data Operations: Startups and mid-sized companies often face the challenge of scaling their data operations as they grow. These organizations need a flexible and cost-effective solution that can handle increasing data volumes and more complex analytics without requiring significant investments in infrastructure.
A Data Lakehouse is well-suited for growing companies due to its scalable architecture and cost efficiency. As these companies expand and generate more data, the Data Lakehouse can grow with them, providing the necessary storage and processing capabilities. Additionally, the unified platform of a Data Lakehouse helps streamline data management and reduces the need for multiple systems, making it easier for growing organizations to maintain and operate their data environment.
Conclusion: In summary, a Data Lakehouse is an excellent choice for:
- Large enterprises with diverse data needs, where the integration of structured and unstructured data can drive more comprehensive insights and streamlined operations.
- Industries with high data complexity, such as financial services, healthcare, and retail, where unified data management and real-time analytics are critical for compliance, operational efficiency, and strategic decision-making.
- Growing companies, including startups and mid-sized businesses, that require a scalable, flexible, and cost-effective solution to support their expanding data operations and evolving analytics needs.
By adopting a Data Lakehouse, these organizations can better manage their data assets, gain valuable insights, and position themselves for future growth and innovation.
8. Major Players in the Data Lakehouse Space
The Data Lakehouse space has rapidly evolved, with several key players providing solutions that cater to various organizational needs. These include major technology providers, open-source projects, and a comparison of key features offered by leading vendors. Here’s a detailed overview:
Technology Providers:
- Databricks: Databricks is a prominent player in the Data Lakehouse market, known for its Unified Analytics Platform that combines the capabilities of data lakes and data warehouses. Databricks offers:
- Delta Lake: An open-source storage layer that brings ACID transactions to Apache Spark and big data workloads. Delta Lake enables reliable data lakes by providing features such as schema enforcement, time travel, and data versioning.
- Databricks Lakehouse Platform: A comprehensive solution that integrates data engineering, data science, and machine learning on a single platform. It provides optimized performance, scalability, and collaborative features for data teams.
- Snowflake: Snowflake is renowned for its cloud-native data warehousing solution and has made significant strides in the Data Lakehouse space. Key offerings include:
- Snowflake Data Cloud: Snowflake provides a Data Cloud platform that combines data warehousing, data lakes, and data sharing capabilities. It supports both structured and semi-structured data, offering a unified experience with seamless data integration and high-performance analytics.
- Snowflake’s Architecture: Snowflake’s architecture separates compute and storage, allowing for scalable and cost-effective data management. Its support for SQL-based querying and integration with various data sources makes it a versatile choice for organizations.
- AWS Lake Formation: AWS Lake Formation is Amazon Web Services’ solution for building and managing data lakes. It offers:
- AWS Lake Formation: A service that simplifies the process of setting up and managing a data lake on AWS. It automates tasks such as data ingestion, cataloging, and security, making it easier to create a unified data repository.
- Integration with AWS Ecosystem: AWS Lake Formation integrates with other AWS services, such as Amazon S3 for storage and Amazon Redshift for data warehousing, providing a comprehensive solution for managing and analyzing data.
Open Source Solutions:
- Apache Hudi: Apache Hudi (Hadoop Upserts Deletes and Incrementals) is an open-source project that provides capabilities for managing large-scale data lakes. Key features include:
- ACID Transactions: Hudi enables ACID transactions on data lakes, providing consistency and reliability for data operations.
- Real-Time Data Processing: It supports near real-time data ingestion and processing, making it suitable for streaming data scenarios.
- Apache Iceberg: Apache Iceberg is another open-source project focused on improving data lake management. Its key features include:
- Table Format: Iceberg provides an open table format for managing large datasets, offering support for schema evolution, partitioning, and time travel.
- Performance Optimization: It is designed to work efficiently with big data processing engines like Apache Spark, Trino, and Presto, enhancing query performance and scalability.
- Delta Lake (Open Source): Originally developed by Databricks, Delta Lake is now an open-source project under the Linux Foundation. It offers:
- ACID Transactions: Delta Lake provides ACID transaction support on data lakes, ensuring data reliability and consistency.
- Optimized Performance: It includes features such as data compaction and indexing to improve query performance and manage large datasets effectively.
Comparison of Key Features:
Feature | Databricks Lakehouse | Snowflake Data Cloud | AWS Lake Formation | Apache Hudi | Apache Iceberg | Delta Lake (Open Source) |
ACID Transactions | Yes | Yes | Limited | Yes | Yes | Yes |
Real-Time Processing | Yes | Yes | Yes | Yes | No | Yes |
Scalability | High | High | High | High | High | High |
Data Types Supported | Structured & Unstructured | Structured & Semi-Structured | Structured & Semi-Structured | Structured & Semi-Structured | Structured & Semi-Structured | Structured & Semi-Structured |
Integration | Strong with Spark | Strong with SQL and BI tools | Strong with AWS ecosystem | Good with big data frameworks | Good with big data frameworks | Good with Spark |
Data Management | Unified Analytics | Unified Data Cloud | Automated Data Management | Flexible with data lakes | Open Table Format | ACID Transactions |
The Data Lakehouse space is populated by several key players, each offering unique solutions and features. Technology providers like Databricks, Snowflake, and AWS Lake Formation offer robust, integrated platforms for managing diverse data needs. Open-source projects like Apache Hudi, Apache Iceberg, and Delta Lake contribute valuable capabilities for data lake management, especially in terms of ACID transactions and real-time processing. Understanding the features and strengths of these solutions can help organizations choose the right Data Lakehouse platform to meet their specific data management and analytics requirements.
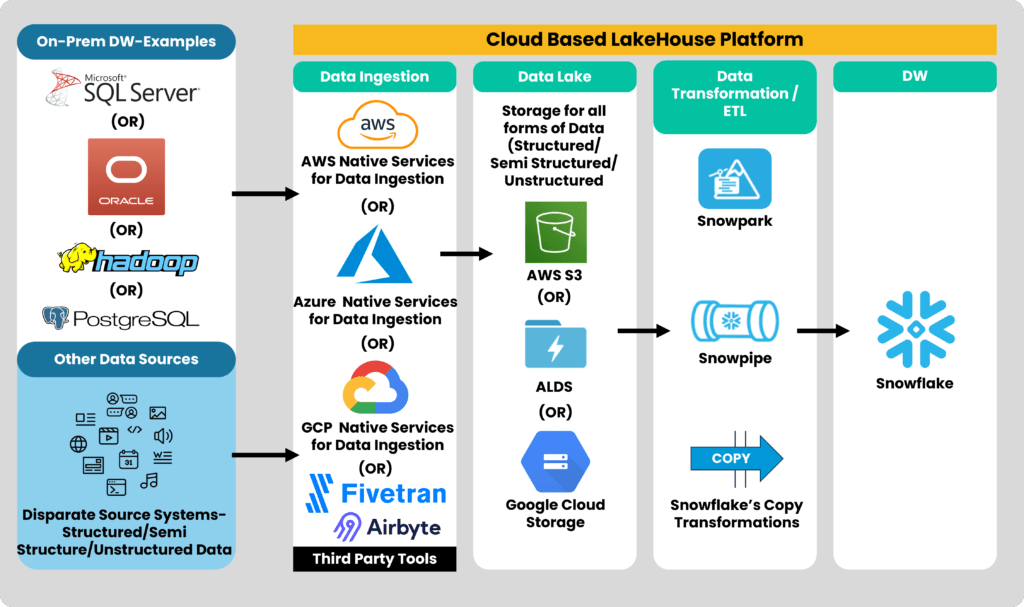
9. Migrating from Data Warehouses or Data Lakes to a Data Lakehouse
Migrating to a Data Lakehouse from existing data warehouses or data lakes can be a transformative step for an organization, offering enhanced capabilities for data management and analytics. However, the migration process requires careful planning and execution to ensure a smooth transition. Below is a detailed guide on how to approach this migration, including strategies, challenges, and real-world case studies.
Assessment of Current Infrastructure:
Importance of Evaluating Existing Systems Before Migration: Before initiating the migration to a Data Lakehouse, it is crucial to assess your current data infrastructure thoroughly. This assessment involves:
- Inventory of Data Assets: Catalog all data sources, data types, and data volumes currently managed by your data warehouse or data lake. Understanding what data you have and how it is structured will help in planning the migration process.
- Assessment of Data Quality and Governance: Evaluate the quality of your existing data, including accuracy, completeness, and consistency. Assess your current data governance practices to ensure that they will align with or be enhanced by the new Data Lakehouse architecture.
- Evaluation of System Performance and Scalability: Analyze the performance and scalability limitations of your current systems. Identifying bottlenecks or inefficiencies can provide insights into how the Data Lakehouse can address these issues.
- Stakeholder Engagement: Engage with stakeholders from various departments to understand their data needs and requirements. Their input will help ensure that the Data Lakehouse meets the needs of all users and supports the organization’s strategic goals.
Migration Strategies:
Step-by-Step Guide to Transitioning from a Data Warehouse or Data Lake to a Data Lakehouse:
- Define Objectives and Scope:
- Clearly define the goals of the migration, such as improved performance, cost savings, or enhanced analytics capabilities. Determine the scope of the migration, including which data sources and workloads will be moved to the Data Lakehouse.
- Choose the Right Data Lakehouse Platform:
- Based on your assessment, select a Data Lakehouse platform that best fits your organization’s needs. Consider factors such as scalability, integration capabilities, and support for various data types.
- Plan the Migration:
- Develop a detailed migration plan that outlines the steps involved, timelines, and resource requirements. Include a risk management plan to address potential issues that may arise during the migration process.
- Data Migration:
- Begin migrating data from the existing data warehouse or data lake to the Data Lakehouse. This may involve:
- Data Extraction: Extract data from the source systems.
- Data Transformation: Transform data into a format compatible with the Data Lakehouse.
- Data Loading: Load the transformed data into the Data Lakehouse.
- Begin migrating data from the existing data warehouse or data lake to the Data Lakehouse. This may involve:
- Integration and Testing:
- Integrate the Data Lakehouse with existing applications and systems. Perform extensive testing to ensure that data is accurately loaded, queries are performing as expected, and the Data Lakehouse meets the defined objectives.
- User Training and Adoption:
- Train users on the new Data Lakehouse platform, including how to access and analyze data. Promote adoption by demonstrating the benefits and providing support during the transition.
- Monitor and Optimize:
- Continuously monitor the performance of the Data Lakehouse and optimize configurations as needed. Gather feedback from users and make adjustments to ensure that the Data Lakehouse is meeting the organization’s needs.
Hybrid Approaches for Phased Migration:
- Phased Migration: Implementing a phased migration approach involves gradually transitioning data and workloads to the Data Lakehouse while maintaining the existing systems. This approach allows for testing and validation of the Data Lakehouse in parallel with the old systems, minimizing disruption.
- Hybrid Architecture: In a hybrid approach, some data remains in the legacy systems while new data is ingested into the Data Lakehouse. This allows organizations to benefit from the Data Lakehouse’s capabilities while gradually moving legacy data over time.
Challenges and Considerations:
Common Challenges:
- Data Migration: Migrating large volumes of data can be complex and time-consuming. Ensuring data integrity and consistency during the migration process is crucial.
- Integration Issues: Integrating the Data Lakehouse with existing applications and data sources may require custom development and adjustments to existing workflows.
- Performance Tuning: Optimizing the performance of the Data Lakehouse to handle various workloads and ensure fast query response times can be challenging.
Best Practices to Overcome Challenges:
- Data Quality Management: Implement robust data quality checks and validation processes to ensure that data migrated to the Data Lakehouse is accurate and complete.
- Incremental Migration: Use incremental migration techniques to move data and workloads gradually, reducing the risk of disruption and allowing for continuous validation and testing.
- Leverage Automation: Utilize automation tools for data extraction, transformation, and loading (ETL) to streamline the migration process and reduce manual effort.
- Collaborate with Vendors: Work closely with the Data Lakehouse vendor for support and guidance throughout the migration process. Vendors often have resources and expertise to assist with complex migrations.
Case Studies:
**1. [Case Study: A Major Retailer’s Migration to a Data Lakehouse]
- Background: A large retail organization needed to unify its data from disparate systems to enhance customer insights and streamline operations.
- Solution: The retailer adopted a Data Lakehouse to integrate structured data from its transactional systems with unstructured data from social media and customer feedback.
- Benefits Realized: Improved customer segmentation, enhanced real-time analytics, and reduced data processing costs.
**2. [Case Study: Financial Services Firm Transitioning to a Data Lakehouse]
- Background: A financial services firm sought to modernize its data infrastructure to support real-time risk analysis and regulatory reporting.
- Solution: The firm implemented a Data Lakehouse to combine its data warehousing capabilities with a data lake for comprehensive risk management and compliance reporting.
- Benefits Realized: Enhanced data accuracy, faster reporting, and better compliance with regulatory requirements.
**3. [Case Study: Healthcare Provider’s Data Lakehouse Adoption]
- Background: A healthcare provider needed to manage patient data from various sources to improve care coordination and research capabilities.
- Solution: The provider migrated to a Data Lakehouse to consolidate EHRs, medical imaging, and patient surveys into a single platform.
- Benefits Realized: Improved patient outcomes through better data integration, enhanced research capabilities, and streamlined data management.
Migrating to a Data Lakehouse involves careful assessment of current infrastructure, strategic planning, and addressing potential challenges. By following a structured migration approach, leveraging hybrid strategies, and learning from real-world case studies, organizations can successfully transition to a Data Lakehouse and realize its benefits in terms of data integration, performance, and scalability.
![]()
10. Conclusion
As organizations navigate the ever-evolving landscape of data management, understanding the role and benefits of Data Lakehouses becomes increasingly vital. Here’s a recap of the key points discussed, a call to action, and insights into the future of data management:
Recap of Key Points:
- Evolution Towards Data Lakehouses: The shift from traditional data warehouses and data lakes to Data Lakehouses represents a significant advancement in data architecture. Data Lakehouses combine the strengths of both systems, providing a unified platform that handles both structured and unstructured data while offering scalability, real-time processing, and cost efficiency.
- Importance of Data Lakehouses: Data Lakehouses are crucial for organizations with diverse data needs, high data complexity, and those preparing for growth. They simplify data management, optimize performance, and democratize data access, making them an attractive solution for modern enterprises.
- Differentiation from Data Warehouses and Data Lakes: Unlike traditional data warehouses, which are optimized for structured data and complex queries, or data lakes, which excel at handling unstructured data but lack transactional support, Data Lakehouses integrate both capabilities into a single platform. They offer hybrid storage formats, ACID transactions, and unified governance, addressing the limitations of previous systems.
- Key Features and Benefits: The Data Lakehouse’s architectural advancements include simplified design, performance optimization, data democratization, and future-proofing. These features make it a powerful tool for managing and leveraging data effectively.
- Major Players and Solutions: Leading technology providers such as Databricks, Snowflake, and AWS Lake Formation offer robust Data Lakehouse solutions. Open-source projects like Apache Hudi, Apache Iceberg, and Delta Lake contribute valuable functionalities to the ecosystem. Understanding these solutions helps organizations make informed decisions about their data architecture.
- Migration Strategies: Transitioning to a Data Lakehouse involves assessing current infrastructure, planning migration strategies, addressing challenges, and learning from successful case studies. A phased or hybrid approach can mitigate risks and ensure a smooth migration.
Call to Action:
We encourage you to take the next step in evaluating your current data infrastructure. Consider whether a Data Lakehouse could enhance your organization’s data management capabilities and address existing challenges. By assessing your needs and exploring available solutions, you can position your organization for improved data integration, analytics, and performance.
Future Outlook:
The future of data management holds exciting possibilities as technology continues to advance. We can expect further innovations in data architecture, including enhanced integration of artificial intelligence and machine learning, more advanced data governance frameworks, and greater emphasis on real-time analytics. As organizations increasingly rely on data-driven decision-making, the role of Data Lakehouses and similar innovations will be pivotal in shaping the future of data management.
As you explore new data solutions and strategies, consider supporting initiatives that foster growth and development in various fields. The MEDA Foundation, dedicated to helping autistic individuals, creating employment opportunities, and promoting self-sufficiency, welcomes your participation and donations. Your support contributes to building self-sustaining ecosystems and creating positive impacts in communities.
For more information on how to get involved or donate, visit MEDA Foundation.
Further Reading:
- “The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling” by Ralph Kimball and Margy Ross
- “Building the Data Lakehouse” by Bill Inmon and Derek Strauss
- “Data Management for Researchers: Organize, Maintain and Share Your Data for Research Success” by Kristin Briney
- “Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems” by Martin Kleppmann








